Pandas 数据处理
pandas 缺失值的处理
利用python对数据进行清洗
python
案例:对特殊excel的数据进行读取、清洗、处理python
# step1. 读取excel时,忽略指定的几个空行
studf = pd.read_excel("xxx路径", skiprows=2)
# step2. 检测空值
studf.isnull() # 会返回bool值
studf.notnull() # 返回的值 与 isnull 相反
studf["分数"].isnull()
# 小案例 利用notnull 筛选出所有 不含空值的 分数行
studf.loc[studf["分数"].notnull(), :]
# step3. 删除掉全是空值的列
studf.dropna(axis="columns", how='all', inplace=True) #inplace=True 表示在原DataFrame上进行修改,而不是返回一个新的DataFrame
# step4. 删除掉全是空值的行
studf.dropna(axis="index", how='all', inplace=True)
# step5. 将分数列为空的填充为0分
studf.fillna({"分数":0}) #或者用下面的方法
studf.loc[:, '分数'] =studf['分数'].fillna(0)
#step6. 将姓名的缺失值进行填充
studf.loc['姓名', :] =studf['姓名'].fillna(method="ffill")
#step7. 将清洗好的excel进行保存
studf.to_excel("路径", index = False)python
总结:
skiprows=2: 忽略指定的空行
xxx.isnull / xxx.notnull :检测DataFrame中的空值
xxx.dropna :删除掉全是空值的行/列
xxx.fillna 是一个用于填充缺失值的方法
method="ffill" 表示使用前一个非缺失值来填充缺失值。
inplace=True 表示在原DataFrame上进行修改,而不是返回一个新的DataFrame
index = False :表示不保存行索引pandas SettingWithCopyWarning报警
python
# 从dataFrame 中选出2018年3月份的数据进行分析
condition = df["ymd"].str.startswith("2018-03")
# 设置温差 两步操作
df[condition]["wencha"] = df["hwendu"] - df["lwendu"]分析
结果:运行上面两行代码后 出现copywarning 报错
逻辑:这是一个链式操作先get 再set,首先将condition 装入 3月份的数据,第二步再添加温差colums
错误原因:第一步 get 步骤没有具体定义 是view 还是copy (view:在源DataFrame直接编辑 ;copy:复制DataFrame 并编辑)
解决逻辑:pandas 的DataFrame的修改操作, 必须在源dataframe 上进行,一步到位
python
# 解决方案1 一步操作
df.loc[condition, "wencha"] = df["hwendu"] - df["lwendu"]
# 解决方案2 copy逻辑, 适用于筛选后 且 后续需要深入研究的数据
df_201803 = df[condition].copy()
df_201803["wencha"] = df["hwendu"] - df["lwendu"]pandas 数据排序
python
# series 的排序
Series.sort_values(ascending = Ture,inplace = False)
# ascening: Ture 升序 False 降序
# DataFrame 的排序
DataFrame.sort_values(by=["表头1", "表头2"], ascending = Ture, inplace = False)
# by: 字符串 或者list<字符串>,单列排序或者多列排序
eg:DataFrame.sort_values(by=["表头1", "表头2"], ascending = [True, False], inplace = False)pandas 字符串处理
python
注:Series处理字符串前,先需要获取str属性 然后在属性上调用函数 DataFrame没有str属性 则不需要调用字符串方法列表和参考文档
链接 打开后 找到series下的 string handing
python
# 判断是不是数字
df["xxxx"].str.isnumeric() #返回True 或 False
# 获取字符串长度
dfdf["xxxx"].str.len()使用str的startswith 、contains、等 得到bool的Series 可以做条件查询
python
condition = df["xxx"].str.startswith("2018-03") # 输出的结果为bool值需要多次str处理的链式操作
案例: 提取201803这样的数字月份
step1:先将2018-03-31替换成20180331的形式
step2:提取月份字符串201803
python
df["年月日"].str.replace("-","")
# 每次调用函数,都返回一个新的Series
df["ymd"].str.replace("-","").str.slice(0, 6) # str.slice 截取每个字符串的前6个字符使用正则表达式的处理
python
# 添加新列
def get_yearmonthday(x):
year,month,day = x[ymd].split("-") # 使用 - 对年数据进行分割 得到三个字符串 年 月 日
return f"{year}年{month}月{day}日"
df["中文日期"] = df.apply(get_yearmonthday,axis = 1)python
#去掉 如2018年03月31日 的 年、月、日
# 方法1
df.["中文日期"].str.replace("年","").str.replace("月","").str.replace("日","").
# 方法2 正则表达式
df.["中文日期"].str.replace("[年月日]","")
# 在Python中,方括号[]用于表示字符集,即匹配方括号内的任意一个字符总结: 正则表达式:Regular Expression 限定符:"?" "*" "+"
pandas的 axis 参数
python
axis = 0 index
axis = 1 colums
聚合操作:指的是跨行/跨列 cross rows/columspython
import pandas as pd
import numpy as np
df = pd. DataFrame(
np.arange (12).reshape (3,4),
columns=['A', 'B', 'C','D']
)
df| A | B | C | D | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 | 7 |
| 2 | 8 | 9 | 10 | 11 |
python
总结
np.arange(12):创建一个包含从0到11的整数的一维数组。
reshape(3, 4):将一维数组重新整形为一个3行4列的二维数组。python
# 单列drop 就是删除某一列 单行drop 就是删除某一行
df.drop("A",axis = 1)
df.drop("1",axis = 0)python
# 按axis = 0/index 执行mean 聚合操作 反直觉: 输出的不是每行的结果 而是每列的结果
df.mean(axis=0)A 4.0
B 5.0
C 6.0
D 7.0
dtype: float64
pandas 的 merge 语法
merge的语法(合并功能)
参考文档ate=None)
python
pandas.merge(
left, right, # 左侧/右侧dataFrame
how='inner', #合并方式,可选值有 'left'、'right'、'outer'、'inner'。默认为 'inner'。
n=None, #用于合并的列名,必须同时存在于左右两侧的 DataFrame 中。如果未指定,则默认使用两个 DataFrame 的列名交集作为合并键。
left_on=None, right_on=None, # 左侧/右侧 DataFrame 中用作合并键的列名。
left_index=False, right_index=False, # 如果为 True,则使用左侧/右侧 DataFrame 的行索引作为合并键。
sort=True, # 是否对结果进行排序,默认为 True。
suffixes=('_x', '_y'), # 用于处理重复列名的后缀,默认为 ('_x', '_y')。
copy=True, # 是否复制数据,默认为 True。
indicator=False, # 是否添加一个名为 _merge 的辅助列,用于标识合并类型,默认为 False。
validate=None) # 检查是否包含重叠的列名,可选值 'one_to_one'、'one_to_many'、'many_to_one'、'many_to_many' None。默认为 None。案例: 将下面的三个表合并成一个完整的大表 有三个文件 1. 用户对电影的评分数据 rating.dat 2. 用户本身信息数据 users.dat 3.电影本身数据 movies.dat
python
df_rating = pd.read_csv("路径", sep="::", engine='python', mames="userID::movieID::Rating::Timestamp".split("::"))
df_users = pd.read_csv("路径", sep="::", engine='python', mames="userID::Gender::Age::Occupation::Zip-code".split("::"))
df_movies = pd.read_csv("路径", sep="::", engine='python', mames="userID::Title::Genres".split("::"))
# 当sep 设置两个字符设置为分隔符时,系统会默认为是正则表达式 我们要在后面添加一个 engine 转义语法 让他识别为python语言
df_rating_users = pd.merge(df_rating, df_users, left_on="MovieID", right_on="MovieID")
df_rating_users_movies = pd.merge(df_rating_users, df_movies, left_on="MovieID", right_on="MovieID")merge 数量对齐的关系
一对一的关系一对多的关系:此时数据会被复制,数量以多的一边为准 多对多的关系:结果数量会出现乘法
理解 left join、 right join、 inner join、 outer join 的区别
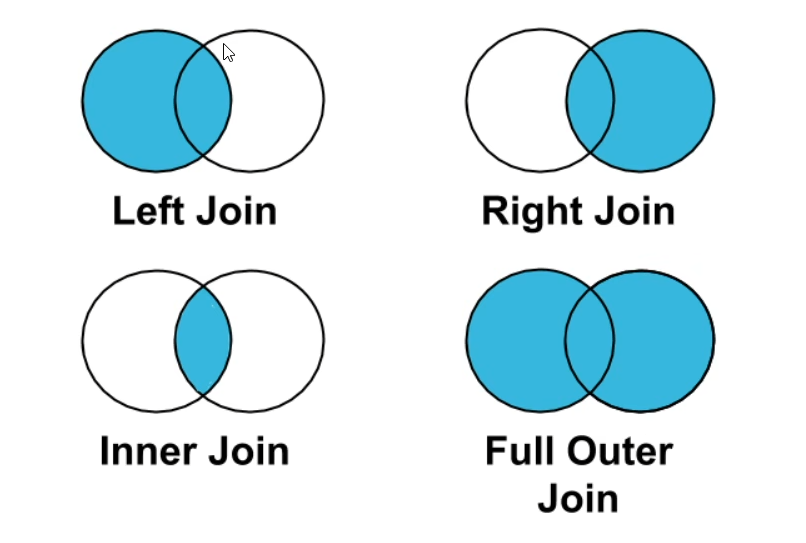
注: 如果出现非key字段重复,该如何处理 引入merge语法:suffixes=('_x', '_y'), # 用于处理重复列名的后缀,默认为 ('_x', '_y')。
pandas 的 Concat 合并
使用场景:批量合并, 给DataFrame 添加行/列
python
import warnings
warings.filterwarnings('ignore')使用pandas.concat 合并数据
python
# concat 默认的参数 axis=0 join= outer gnore_index=False
pd.concat([df1, df2])
# 使用axis 特性来添加多列
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3'],})
s1 = df1.apply(lambda x:x["A"+"_GG"], axis=1)
s2.name = "G" # 构造 表头为 G 列
pd.concat([df1,s1,s2], axis=1)
pd.concat([s1,s2], axis=1) # 列表中没有df1 输出结果仍然和上一行代码相同python
### 12.1 使用append 按行 合并数据 (表格的 index 变多)
首先构造 df1 和df2
df1.append(df2, ignore_index-True) #忽略原来的索引(重建索引)
# 一行一行的给dataFrame 添加数据
# 方法1
df = pd.DataFrame(colums=['A'])
for i in range(5) #这是一个循环,i的值会从0变化到4。
df = df.append({'A':i}, ignore_index=True)
# 方法2 更优解
# 第一个入参是一个列表,避免了多次复制
pd.concat(
[pd.DataFrame([i], columns=[A]) for i in range(5)],
ignore_index=True
)
# pd.concat() 函数用于将多个DataFrame对象进行连接操作。
#[pd.DataFrame([i], columns=[A]) for i in range(5)] 是一个列表推导式,它会生成一个包含5个DataFrame对象的列表。每个DataFrame对象都只有一个元素,即从0到4的整数。pandas 文件的合并和拆分
python
#定义需要处理文件的目录:
work_dir ="xxxxx"
#定义需要处理结果存放目录:
output_dir =f"{work_dir}/output"
# f字符被称为格式化字符串,大括号{}里面可以直接写变量名,Python会自动将变量替换为变量名对应的值
import os
if not os.path.exists(output_dir)
os mkdir(output_dir) # 如果路径不存在,则创建
# 找到待处理文件,
df_source = pd.read_excel(f"{work_dir}/xxx.xlsx")
df_source.shpae # 会返回行和列的数量
# 把目标文件 拆分给这六个人 AA BB CC DD EE FF
user_names = ["AA", "BB", "CC", "DD", "EE", "FF"]
# 计算每个人的任务数目
split_size = total_row_count // len(user_names) # 用行数除以人数
if total_row_count % total_row_count != 0 # % 表示余数 != 表示不等于
split_size += 1 # 让split_size 值+ 1 表示余数分配给前面的人进行处理
# 拆分成多个DataFrame
df_subs =[]
for idx, user_name in enumerate(user_names): #enumerate(user_names):将一个可迭代对象(如列表、元组等)转换为一个枚举对象。 idx:索引 user_name:名称
# iloc的开始索引
beign = idx*split_size
# iloc的开始索引
end = beign+split_size
# 实现df 按照iloc 拆分
df_sub = df_source.iloc[beign:end] # (数据框)
# 将每个子df存入列表
df_subs.append((idx, user_name, df_sub))
#将每个dataFrame 存入excel
for idx,user_name, df_sub in df_subs:
file_name =f"{output_dir}/xxxx_{idx}_{username}.xlsx"
df_sub.to_excel(file_name, index=False)将多个小文件合并成一个大文件
python
# 遍历文件 得到要合并的excel名称列表
import os
excel_names = []
for excel_name in os.listdir(output_dir):
excel_names.append(excel_name) # 读取文件名 并添加到excel_name的数据中
# 分别读取到DataFrame
for excel_name in excel_names: # 遍历excel_names 并赋值 给excle_name
#读取每个excel到df
df_split = pd.read_excel(f"{output_dir}/{excel_name}")
#得到username
username = excel_name.replace("xxxx_", "").replace("xlsx", "")[2:] # 从第三个字符开始截取剩余的字符串
print(excel_name, username)
#给每个df 添加1列, 即用户名字
df_split["username"] = username
df_list.append(df_split)
# 使用pd.concat 进行合并
df_merged = pd.concat(df.list)
#将合并后的pd 输出到excel
df.merged to excel(f"{work_dir}/xxx.xlsx", index=False)